Modeling Structural and Functional Patterns of Proteins
Do parameters of protein portray any predictive patterns?
computational biochemistry, computational modeling, protein, data science
Executive Summary
This study investigates the relationship between a protein’s functional classification, its structural characteristics, and its amino acid sequence. By analyzing proteins as polymers with quantifiable physicochemical properties—such as molecular weight, hydrophobicity, amino acid composition, and entropy — we aim to uncover predictive patterns within the dataset. Protein data from three different organisms (30_000 proteins) were obtained from UniProt to ensure both reliability and diversity in the sample.
Proteins are chains of 20 distinct amino acids structured as: 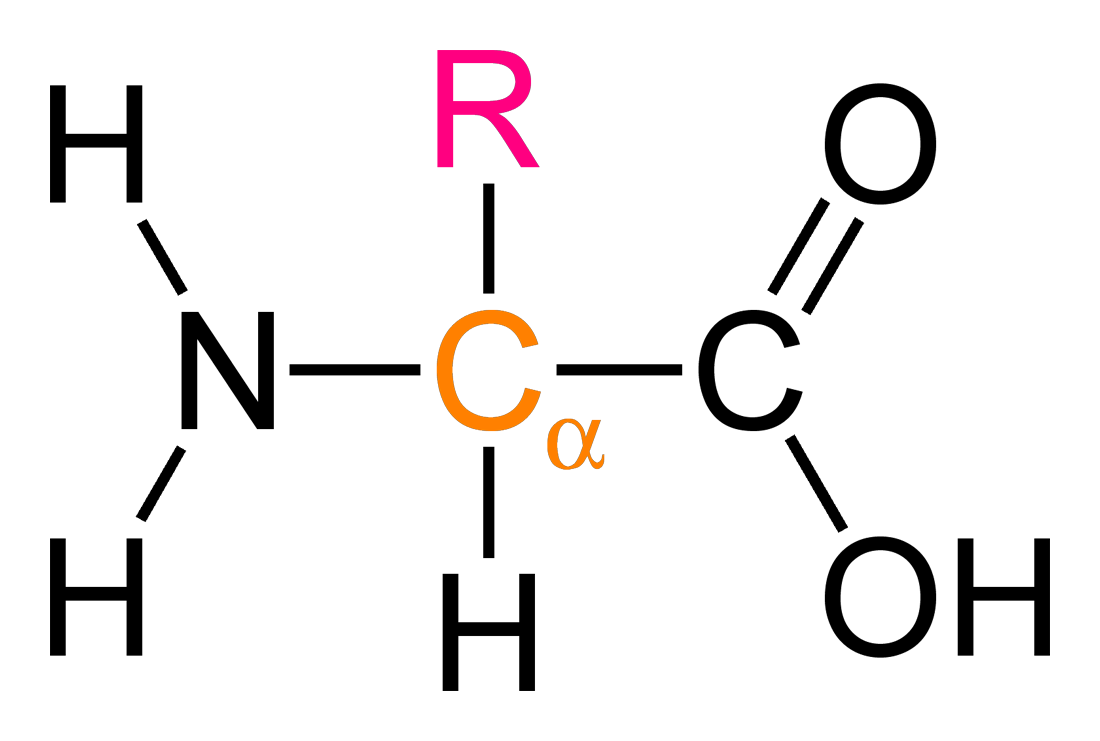
where R group is the variable side chain.Although the chemical properties of individual amino acids are comprehensively established, forecasting the behavior of the complete chain inside an actual biological system nested inside more complex systems presents a significant difficulty. Optimal chemical conditions seldom occur in reality, resulting in noise and unpredictability. This intricacy offers a significant opportunity for computational methods. Through numerical modeling, we may connect basic sequence data with intricate biological functions.
The study concludes:
Despite hundreds of millions of years of evolutionary divergence, physicochemical characteristics of over 30,000 proteins from three mammalian proteomes remained remarkably intact. Instead of being arranged into distinct clusters, protein sequence space is a continuous physicochemical manifold in which location indicates biophysical function rather than species identity. While sequence complexity functions nearly totally independently of protein length, size-dependent trends in hydrophobicity are real but weak, suggesting that proteome composition is shaped by layered and mostly orthogonal evolutionary processes.
Purpose of this project
This project is the fourth in a set of hands-on data science activities. The main objective was to become more proficient with the computational ecosystem of Python, with a focus on using machine learning modeling tools on biological data. I also wanted to use pandas for data manipulation as a simplified substitute for more conventional SQL databases, to better understand it’s capabilities in more deapth.
A significant focus was placed on understanding and implementing an ETL (Extract, Transform, Load) pipeline. While mastering the intricacies of robust ETL design is an ongoing journey, this project provided a foundational understanding of data engineering workflows. The insights gained here directly informed subsequent analyses, evidently the latter study on R&D Spendings of Countries and Results where the undestanding of the purpose and process of ETL implementation became much clearer.
Coming from a physics background rather than biology, this study has been an exercise in stepping outside my comfort zone. It demonstrates the power of applying numerical and computational tools to hyper-specialized research fields, yielding fascinating results even without domain-specific expertise.